论文:Real-Time Loop Closure in 2D LIDAR SLAM
Abstract
为了实现实时的回环检测,cartographer使用分支定界法计算scan-to-map匹配作为约束
Introduction
本文的重点是减少大量数据下回环所需的计算量
Related work
匹配
- Scan-to-scan matching:累计漂移误差大
- Scan-to-map matching:累计漂移误差小,需要好的初始值,用高斯牛顿法找局部最优值
- Pixel-accurate scan matching:漂移误差小,但计算量大
- 减少计算量的策略:通过laser特征提取匹配
- 加强回环检测的策略:直方图统计匹配、提取laser特征、机器学习
scan to scan match:两帧激光雷达数据之间的匹配。假如当前帧的激光雷达数据为A,和它匹配的另一帧激光雷达数据为B,如果以A为起始帧,B为目标帧,那么A经过一个相对平移和旋转变换到B,我们目的就是求出这个相对平移量和旋转角度。目前来说,匹配效果最好的算法就是ICP(Iterative Closest Point)方法,它充分利用了激光雷达每个数据点来进行匹配,后来所有ICP变种基本都是为了提高计算效率而演化的,如何减小循环次数加快收敛等等。
scan to map match:即激光雷达扫描数据直接与地图进行匹配,得到实际位置坐标[x,y,theta]。这种方式一边计算位置,一边把新扫描到的数据及时加入到先前地图中。
减少局部累计误差
- 粒子滤波:对于grid-based SLAM,占用计算资源过多
- 基于图优化的SLAM:node表示位姿和特征,边表示观测约束
粒子滤波:通过寻找一组在状态空间中传播的随机样本来近似的表示概率密度函数,用样本均值代替积分运算,进而获得系统状态的最小方差估计的过程,这些样本被形象的称为“粒子”,故而叫粒子滤波。附一个非常生动的说明
System overview
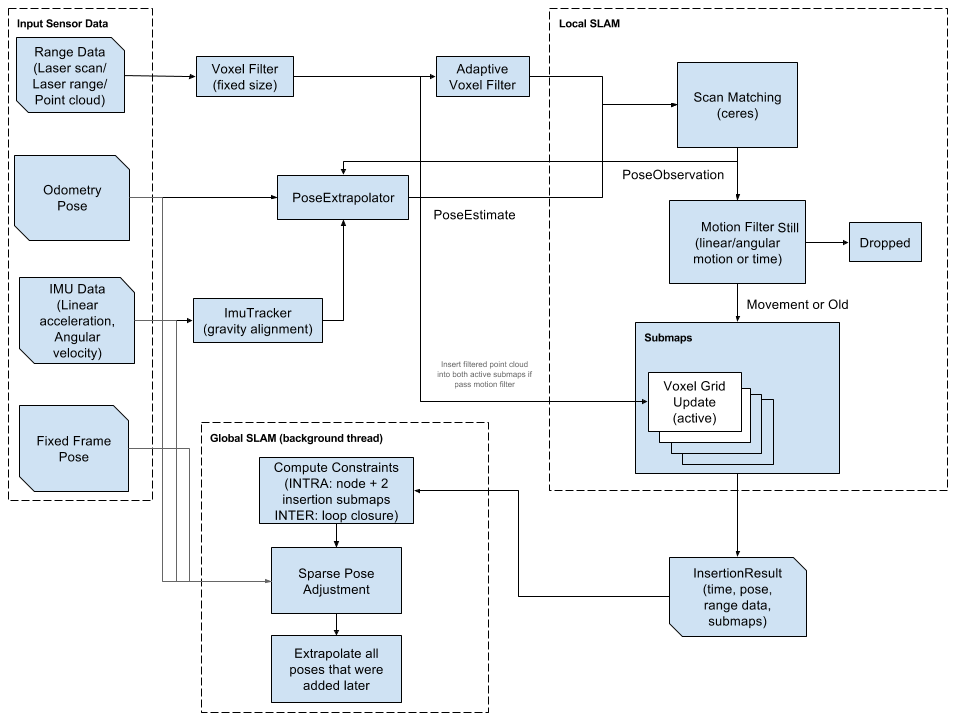
- 将laser scan插入submap中最合适的位置,假设该位置短时间内足够准确
- Scan matching针对于当前submap进行,所以只依赖于当前scan,会累积全局误差
- 位姿优化:
- 当submap完成后(即没有新scan插入submap),submap将进行扫描匹配以检测回环
- 所有结束的submap和scan会自动进行回环
- If they are close enough based on current pose estimates, a scan matcher tries to find the scan in the submap.(没理解指谁和谁比较,submap不是由scan组成的吗?包含的关系还能远吗?)
- 若在当前估计位姿周围的搜索窗口中找到了较好匹配,则将其作为回环约束加入优化问题
- 软约束:回环扫描匹配需比新增scan快一些,否则会有明显滞后
- 通过branch-and-bound和子图预算栅格加速回环检测(如何实现?)
Local 2D SLAM
- 局部slam和全局slam的优化对象都是 pose($\xi x$ , $\xi y$ , $\xi \theta$)
- 不平稳测量平台(如背包)需要结合IMU,获取雷达相对于重力的方向,以将scan映射到2D平面
- scan matching:用非线性优化对齐scan和submap,会产生累计误差,由全局方法消除
A. scans
- submap的构造是重复对齐scan和submap坐标系的迭代过程
- scan坐标系—>submap坐标系:
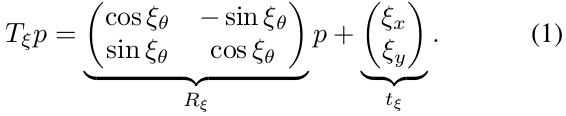
B. submaps
(翻译成子图的话,这里的图是map而不是graph,容易产生歧义)
- submap由几个连续的scan构建
- submap采用栅格地图的形式,每格边长5cm,每格的值表示该格阻塞(有障碍物)的概率
- pixel:某格点周围一圈格点
- 新增scan时,击中则更新击中点,为击中则更新一条射线
- 更新每格概率:
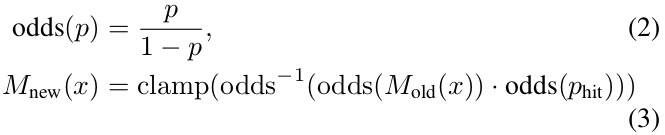
C. Ceres scan matchng
除第一个submap外,新增scan会插入相邻两个submap
将scan插入submap之前,需要用基于ceres的scan matcher根据当前局部submap优化pose $\xi$
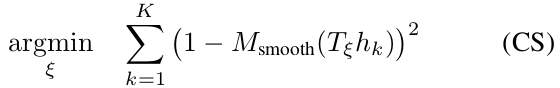
- $T_\xi$将$h_k$由scan坐标系变换至submap坐标系
- Msmooth是平滑函数,用双三次插值减小[0,1]外点的影响
bicubic函数:
Closing loops
- 大空间通过创建许多小submap处理
- 用稀疏位姿矫正(SPA)来优化所有scan和submap
- 插入scan的相对位姿存储在内存中,将在优化回环时使用。
- 一旦submap结束(不再新增scan),scan和submap就进行回环检测
- Scan matcher在后台运行,一旦找到好的匹配,就将相对位姿加入优化问题
A. Optimization problem
- 回环优化和扫描匹配一样,也是一个非线性最小二乘问题
- 每隔几秒,用ceres计算下述问题的解:(Sparse Pose Adjustment)
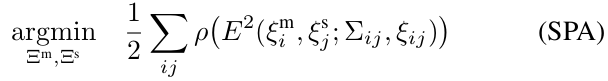
- $E_m$=$\xi_{mi}$ (i=1,…,m)是submap位姿,$E_s$=$\xi_{sj}$ (i=1,…,s)是scan位姿,在给定约束条件下进行优化
- 这些约束用相对位姿 $\xi_{ij}$ 和相关协方差矩阵 $\Sigma_{ij}$ 描述
- 对于一对submap i和scan j,位姿 $\xi_{ij}$ 描述了submap坐标系中scan匹配到的位置
- 此类约束的残差由下式计算:
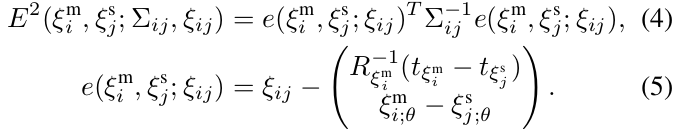
- 损失函数$\rho$(例如huber损失函数)用于减少异常值的影响。这些异常值可能出现在scan matching向优化问题SPA增加不正确的约束时,例如像办公室隔间这样的局部对称空间。
hube loss: 相比于最小二乘的线性回归,HuberLoss降低了对离群点的惩罚程度。当预测偏差小于 $\delta$ 时,采用平方误差;当预测偏差大于 $\delta$ 时,采用线性误差。
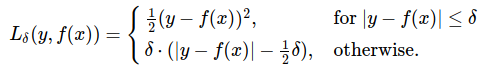
B. Branch-and-bound scan matching(BBS)
- pixel-accurate scan matching:
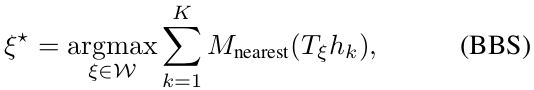
- W是搜索窗口,$M_{nearest}$是submap周围一圈格点
- 使用前面的CS公式可以提高匹配质量
- 搜索步长对效率有很大影响
- 选择角度步长 $\delta_\theta$ 使得扫描范围最大$d_{max}$处的扫描点移动不超过pixel的半径r,由余弦定理得:
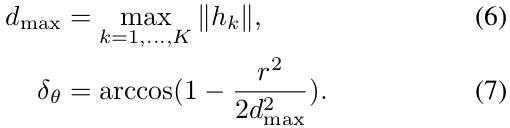
- 计算一个完整的步数,覆盖给定的搜索窗口(例如$W_x$=$W_y$=7m,$W_\theta$=30度),并对其取整
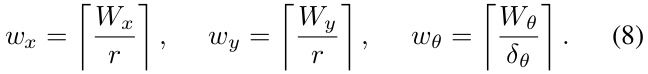
- 产生一个有限集合W形成以估计位姿 $\xi_\theta$ 为中心的搜索窗口
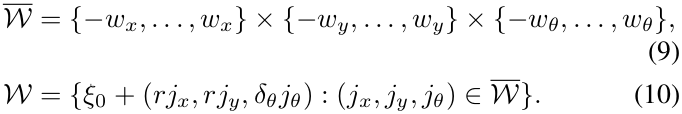
- 选择角度步长 $\delta_\theta$ 使得扫描范围最大$d_{max}$处的扫描点移动不超过pixel的半径r,由余弦定理得:
- 朴素的暴力搜索太慢

- 用Branch-and-bound分支定界法在较大搜索窗口下求解BBS问题

分支定界法:通常,把全部可行解空间反复地分割为越来越小的子集,称为分支;并且对每个子集内的解集计算一个目标下界(对于最小值问题),这称为定界。在每次分枝后,凡是界限超出已知可行解集目标值的那些子集不再进一步分枝,这样,许多子集可不予考虑,这称剪枝。这就是分枝定界法的主要思路。
要将分支定界法具体化,我们需要选择节点选择、分支、上界计算的方法
1. Node selection
默认采用深度优先搜索DFS(利用栈的先进后出实现)
- 为避免加入坏匹配作为回环,引入一个分数阈值,小于阈值不予考虑。在实践中,通常不会超过阈值,这降低了节点选择和初始值的重要性。
- 计算每个子节点的分数上限,首先访问上限最大 最有希望的子节点

2. Branching rule
- 树上的每个节点用一组整数表示 c=($c_x$,$c_y$,$c_\theta$,$c_h$),高度$c_h$处的节点有$2^{ch}*2^{ch}$种组合,但只表示特定的旋转。子节点的高度为$\theta$,则对应可行解。
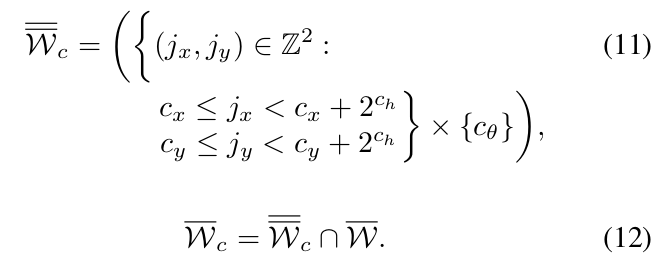
- 将节点分为4个子节点
分支:对一个大的步长在 x 和 y 方向进行对半拆分,而 $\theta$ 不变。对 x 和 y 都进行减半操作,相当于“分田”,在空间坐标上将搜索空间划分为四个更小的区域
3. Computing upper bounds
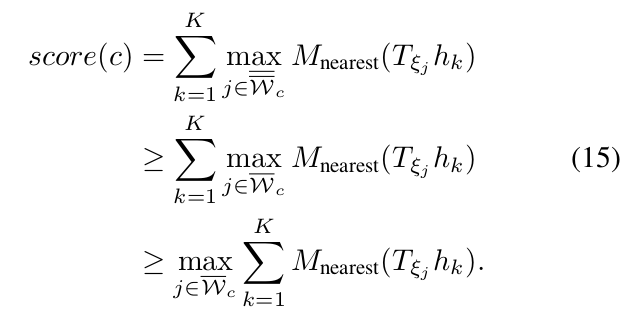
-
为了提高效率,使用预算网格图
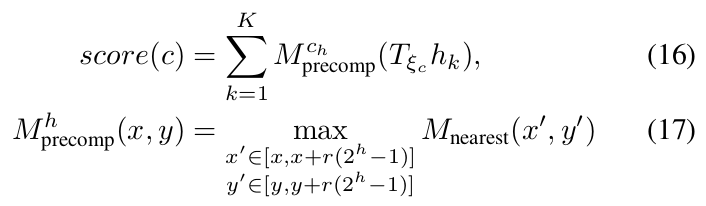
-
$M_{precomp}$和$M_{nearest}$一样有pixel结构,但每个pixel存储着$2^h*2^h$大的搜索窗口中的最大值
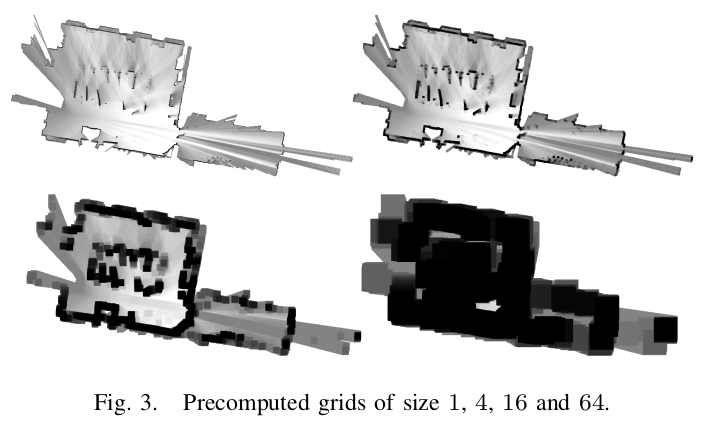
- 对于每个预算格,计算从这格开始的$2^h$宽的行的最大值。用它作为中间结果,构建下一个预算图。用这种方式,时间复杂度是O(n),n为每个预算图中pixel个数
- 另一种计算上界的方式是计算分辨率较低(将分辨率依次减半)的概率栅格图,较省空间,但效果较差。
预算图的内核思想:运动是相对的,与其遍历计算所有可能位姿对应的scan(墙),不如计算固定位姿扫描到的 ”移动“ 的墙。
Conclusions
- cartographer是一个2D SLAM系统,将scan-to-submap匹配回环检测和图优化相结合
- 单个子图轨迹由基于栅格的local SLAM建立
- 在后端,所有scan和submap都用pixel-accurate扫描匹配,以创建回环约束
- scan和submap的约束在后端周期性进行优化
