第12讲 回环检测
12.1 回环检测概述
12.1.1 回环检测的意义
回环检测模块能够给出除了相邻帧之外的一些时隔更加久远的约束。
在某些时候,我们把仅有前端和局部后端的系统称为VO,而把带有回环检测和全局后端的系统称为SLAM。
12.1.2 方法
朴素的方法:
- 暴力法:对任意两幅图像都做一遍特征匹配
- 随机法:随机抽取历史数据并进行回环检测
预计哪出可能出现回环:
- 基于里程计的几何关系(Odometry based)(存在倒为因果的假设,累积误差较大时不适用)
- 基于外观(Appearance based)(词袋模型BoW)
12.1.3 准确率和召回率
 假阳性又称感知偏差,假阴性又称感知变异。
假阳性又称感知偏差,假阴性又称感知变异。
准确率:Precision=TP/(TP+FP),描述算法提取的所有回环中确实是真实回环的概率。
召回率:Recall=TP/(TP+FN),描述在所有真实回环中被正确检测出来的概率。
在SLAM中,我们对准确率的要求更高,对召回率则相对宽容(宁可放过一千,绝不错杀一个!hhh)。
12.2 词袋模型
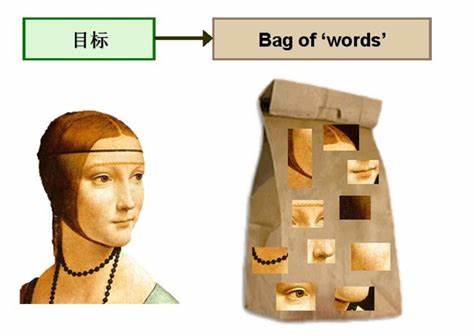 用 “图像上有哪些特征” 来描述一幅图像,假设字典为[眼,鼻,口,手],则一幅仅包含一张人脸的图像可描述为[2,1,1,0]或[1,1,1,0](不考虑数量),与特征的空间位置和排列顺序无关。
用 “图像上有哪些特征” 来描述一幅图像,假设字典为[眼,鼻,口,手],则一幅仅包含一张人脸的图像可描述为[2,1,1,0]或[1,1,1,0](不考虑数量),与特征的空间位置和排列顺序无关。
根据这两个向量,设计一定的计算方式,就能确定图像间的相似性。比如可以定义(1),其中范数取L1 范数,即各元素绝对值之和。在两个向量完全一样时为1,完全相反时为0。
$ s(a,b)=1-\frac1W||a,b||_1 \tag{1} $
考虑到字典通用性,通常会使用一个较大规模的字典,以保证当前使用环境中的图像特征都在其中。
12.3 字典
12.3.1 字典的结构
一个单词与一个单独的特征点不同,它不是从单幅图像上提取出来的,而是某一类特征的组合。所以,字典生成问题类似于一个聚类问题(Clustering)。
每个单词可以看作局部相邻特征点的集合,字典生成问题可以用经典的K-means(K均值)算法解决,步骤如下。
- 随机选取k个中心点
- 对每个样本,计算他们与每个中心点之间的距离,取最小的作为它的归类
- 重新计算每个类的中心点
- 如果每个中心点的变化很小,则算法收敛,退出;否则返回第2步重复
为了提高查找效率,使用k叉树来表达字典。假定有N个特征点,希望构建一个深度为d 、每次分叉为k的树,那么做法如下:
- 在根节点,用k-means把所有样本聚成k类(实际中为保证聚类均匀性会使用k-means++)。这样得到了第一层。
- 对第一层的每个节点,把属于该节点的样本再聚成k类,得到下一层。
- 以此类推,最后得到叶子层。叶子层即为所谓的Words。
12.4 相似度计算
12.4.1 理论部分
我们希望对单词的区分性或重要性加以评估,给它们不同的权值以起到更好的效果。
在文本检索中,常用的一种做法称为TF-IDF(Term Frequency–Inverse Document Frequency),或译频率-逆文档频率 。TF部分的思想是,某单词在一幅图像中经常出现,它的区分度就高。另一方面,IDF的思想是,某单词在字典中出现的频率越低,则分类图像时区分度越高。
在词袋模型中,在建立字典时可以考虑IDF部分。我们统计某个叶子节点$w_i$中的特征数量相对于所有特征数量的比例作为IDF部分。假设所有特征数量为n ,$w_i$数量为$n_i$,那么该单词的IDF为(2)。另一方面,TF部分则是指某个特征在单幅图像中出现的频率。假设图像A 中单词$w_i$出现了$n_i$次,而一共出现的单词次数为n,那么TF为(3)。于是,$w_i$的权重等于TF乘IDF之积(4)。考虑权重以后,对于某幅图像A,它的特征点可对应到许多个单词,组成它的Bagof-Words(5)。
$ IDF_i=\log\frac n{n_i} \tag{2} $
$ TF_i=\frac {n_i}n \tag{3} $
$ \eta_i=TF_i\times IDF_i \tag{4} $
$ A=\begin{Bmatrix}(w_1,\eta_1),(w_2,\eta_2),\cdots,(w_N,\eta_N)\end{Bmatrix}\triangleq v_A \tag{5} $
给定$v_A$和$v_B$,如何计算它们的差异呢?这个问题和范数定义的方式一样,存在若干种解决方式,比如L1范数形式:
$ s(v_A-v_b)=2\sum^N_{i=1}(|v_{Ai}|+|v_{Bi}|-|v_{Ai}-v_{Bi}|) \tag{6} $
12.5 实验分析与评述
12.5.1 增加字典规模
当字典规模增加时,无关图像的相似性明显变小了。而相似的图像,例如图像1和10,虽然分值也略微下降,但相对于其他图像的评分,却变得更为显著了。这说明增加字典训练样本是有益的。
12.5.2 相似性评分的处理
仅仅利用相似性不一定合适,比如办公室往往有很多同款桌椅。所以我们会先取一个先验相似度,表示某时刻关键帧图像与上以时刻关键帧的相似性,然后其他的分支都参照这个值归一化。
比如说,如果当前帧与之前某关键帧的相似度超过当前帧与上一关键帧相似度的3倍,就认为可能存在回环。
12.5.3 关键帧的处理
用于回环检测的帧最好是稀疏一些,彼此之间不太相同,又能涵盖整个环境。
12.5.4 检测之后的验证
词袋的回环检测算法完全依赖于外观而没有利用任何的几何信息,这导致外观相似的图像容易被当成回环。并且,由于词袋不在乎单词顺序,只在意单词有无的表达方式,更容易引发感知偏差。所以,在回环检测之后,我们通常还会有一个验证步骤
- 时间一致性检测:设立回环的缓存机制,认为单次检测到的回环并不足以构成良好的约束,而在一段时间中一直检测到的回环,才认为是正确的回环。
- 空间一致性检测:对回环检测到的两个帧进行特征匹配,估计相机的运动。然后,再把运动放到之前的Pose Graph中,检查与之前的估计是否有很大的出入。