论文:LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping
Abstract
- 3D雷达、单目相机、IMU
- LVI-SAM建立在因子图上,由两个子系统组成:视觉惯性系统(VIS)和激光雷达惯性系统(LIS)
- 两系统紧耦合
- VIS利用LIS初始化
- LIS的深度信息帮助VIS提高视觉特征的精度
- LIS利用VIS的估计结果作为扫描匹配的初始值
- 回环先由VIS识别,再由LIS优化
- 两子系统任一故障,LVI-SAM仍可以进行,从而提高无纹理无特征环境下的鲁棒性
Introduction
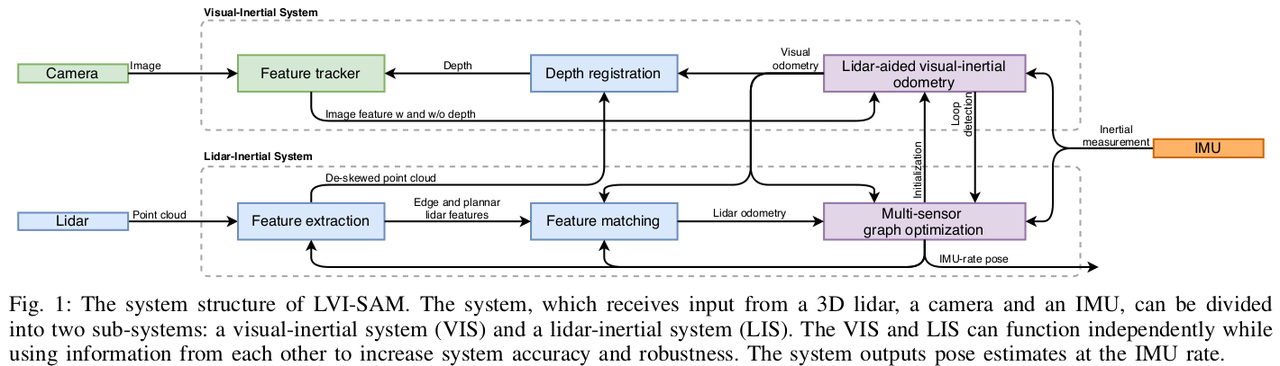
- VIS进行视觉特征跟踪,并可选用LIS提取特征的深度
- VIS通过优化视觉重投影误差和IMU测量获得视觉里程计,可作为雷达扫描匹配的初始值,并将约束引入因子图
- 使用IMU测量值进行点云校准后,LIS将提取雷达的边和面特征,并将其与滑动窗口中的特征图进行匹配
- LIS估计出的系统状态可用于VIS初始化
- 回环先由VIS识别候选匹配,再由LIS优化
- 在因子图中共同优化视觉里程计、雷达里程计、IMU预积分、闭环等约束条件
- 利用优化的IMU偏置项传播IMU测量值,以IMU的速率进行状态估计
VIS
- VIS采用VINS-MONO,特征点用”Good Features To Track”,KLT稀疏光流跟踪法
- 初始化:首先初始化LIS获得系统状态x和b,然后根据图像时间戳将他们插入并关联到每个图像关键帧,最后使用LIS估计的x和b作为VIS的初始值
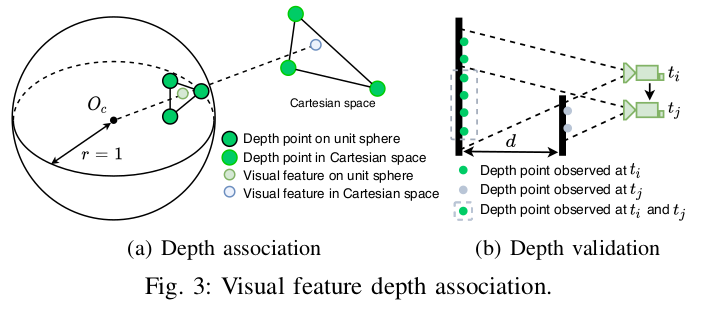
- 特征深度:首先将视觉特征和雷达点投影到以相机为中心的单位球体上,然后对深度点下采样至恒定密度,并用极坐标存储。对于一个视觉特征,通过极坐标搜索二维K-D树,找到球体上离该视觉特征点最近的3个深度点。特征深度就是相机中心到视觉特征,与笛卡尔空间中的3个深度点形成的平面相交的线段(如下图Depth association,特征深度为Oc到浅蓝色点的线段)。另外还需验证深度,计算3个特征点之间的特征距离,如果最大距离超过2m,则该特征点没有深度信息。
- 回环检测:用DBoW2进行回环检测。对于每个新图像关键帧,提取BRIEF描述子,与先前的描述子进行匹配。把DBoW2返回的回环候选图像时间戳发送到LIS进行进一步验证。
LIS
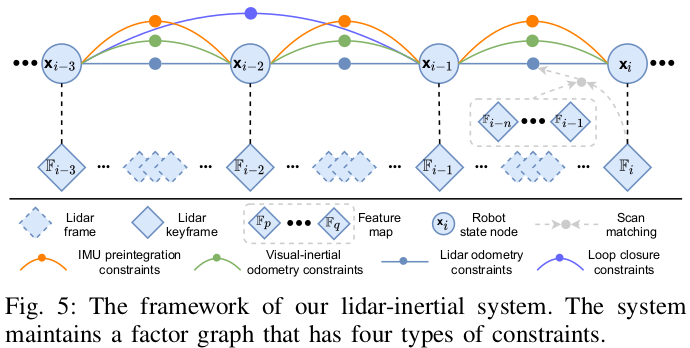
- LIS采用LIO-SAM,用因子图实现全局优化
- 4种约束添加到图中联合优化:IMU预积分约束、视觉里程计约束、雷达里程计约束、回环约束
- 雷达约束来自扫描匹配,当前雷达关键帧和全局特征图进行匹配
- 回环约束由VIS提供,再由扫描匹配优化
- 初始化:初始化之前假设机器人静止,假设IMU的偏置和噪声为0,两帧雷达算出平移旋转作为初始值。初始化之后,从因子图中估计IMU偏置、机器人位姿、速度,然后发给VIS进行初始化。初始化之后可以由VIS或校正后的IMU获得初始值。
消融实验
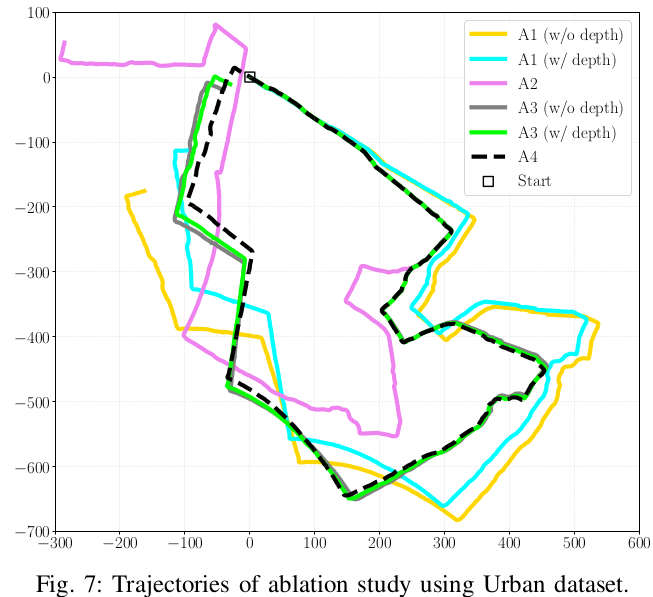
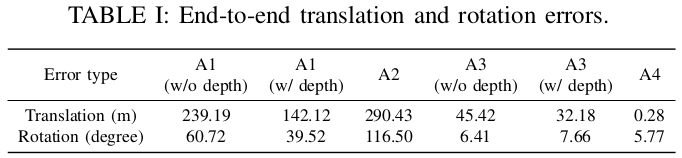
该场景由于植被茂密,GPS信号差,所以在同一位置开始和结束录制数据,比较起点和终点的平移和旋转误差
- A1:VIS
- A2:LIS
- A3:VIS+LIS,激光为视觉提供深度信息,没有视觉回环
- A4:VIS+LIS,激光为视觉提供深度信息,有视觉回环(完整系统)
表格中的w/o表示without,w/表示with
A1中的with depth深度信息来自于雷达,VIS并不是完全不使用雷达,详见VIS部分
代码
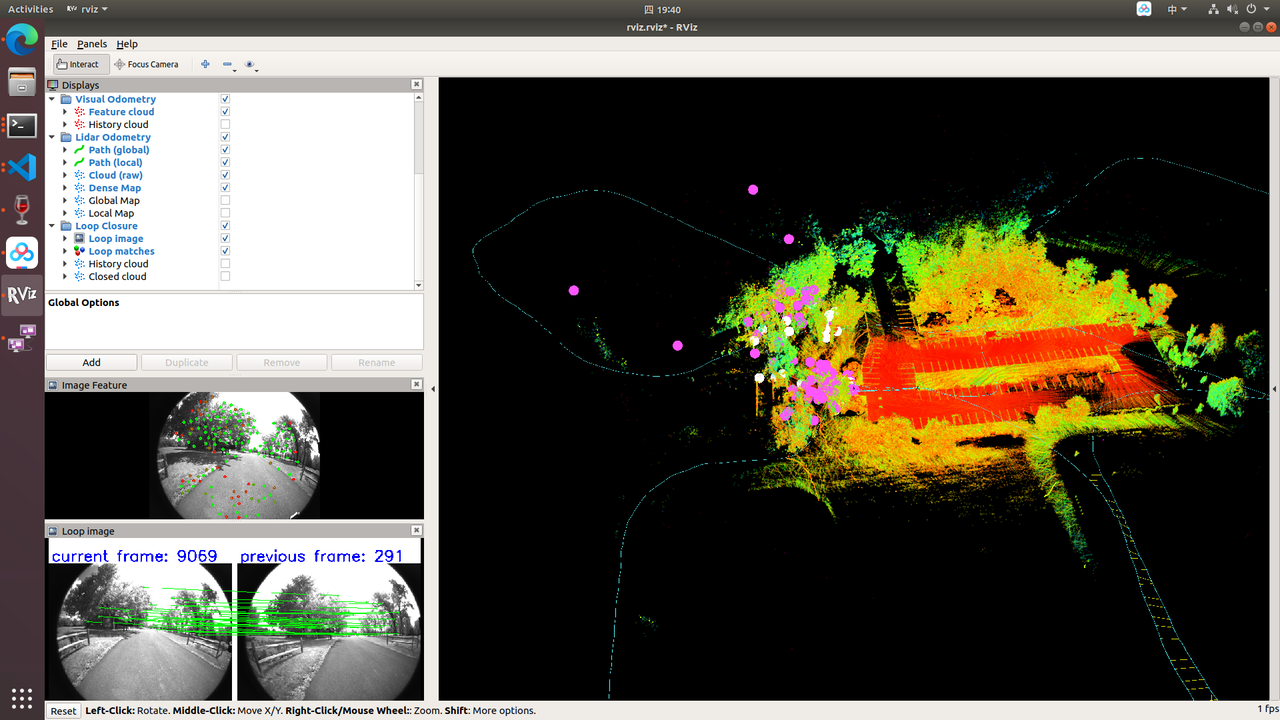
rviz
rqt_graph